Espérance conditionnelle et application en modélisation
Partager :
agrégation : leçon 403 en option probabilité
0.Introduction
1) Filtrage de Kalman-Bucy
On dispose d'un mobile dont la trajectoire est régie par l'équation différentielle:
Cependant le mobile est soumis à desperturbations , et l'on ne dispose que de mesures discrètes portant sur la position du mobile:
où correpond au bruit perturbant l'appareil de mesure.
Finalement en discrétisant on obtient:
Le but va être de trouver deux estimateurs, l'un permettant de prédire à partir des premières
observations, et l'autre d'estimer à l'aide des premières observations.
2) Standard téléphonique
On suppose que le temps d'attente à un standard téléphonique suit une loi , inconnue
On veut estimer à partir de la connaissance du temps d'attente de personnes.
On connait l'estimateur empirique , cependant on va chercher un estimateur qui soit optimal en ce sens qu'il sera de variance inférieure.
3) Sondage stratifié
On réalise un sondage, sur un échantillon représentatif de la population, à propos d'un referendum, et l'on classe les personnes interrogées selon classes distinctes.
Soit et la classe de la personne.
On peut observer que si l'on se restreint a l'une des 3 classes l'espérance de n'est plus la même.
On peut noter .
Et plus généralement si et sont deux variables aléatoires discrètes à valeurs respectives dans et .
Soit un espace de probabilité. une sous tribu.
I.Espérance conditionnelle
Définition: Soit , on appelle espérance conditionnelle de sachant , la projection de sur et on la note
Remarque:
L'espérance conditionnelle minimise parmi les fonctions -mesurable.
L'espérance conditionnelle même si elle est considérée comme une variable aléatoire n'est en fait définie que presque surement.
Théorème: Soit , alors il existe une variable aléatoire -mesurable vérifiant:
et .
On note
Remarque: En particulier si est un représentant de l'espérance conditionnelle de sachant , vérifie,
Propriété: Si est une partition de , avec et .Soit alors .
De plus si et peut être choisi arbitrairement dans le cas contraire.
II.Propriétés
Premiers résultats:
L'espérance conditionnelle possède les mêmes propriétes que l'espérance classique (linéarité, croissance monotone, lemme de Fatou, Cv dominé...)
Si indépendante de alors
Si est -mesurable et en particulier .
Exemple: Si sont des va iid et , on peut montrer que et .
Proposition Si , alors p.s.
Proposition: martingale associée à une filtration, alors à fixé,
.
De plus est constant.
Exemple: Urne de Polya, si correspond a la proportion de boule blanche à la k-ème étape.
Sachant que , on a qui est une martingale et
III.Filtre de Kalman-Bucy.
1) Vecteurs gaussiens
Définition: Si et sont deux vecteurs aléatoires on définit .
Proposition: Si et sont deux vecteurs gaussiens dans leur ensemble, de moyenne et et de matrices de covariances et .
Notons , et suppososns positive.
Alors .
Et la covariance de est .
Corollaire: Si sont trois vecteurs gaussiens dans leur ensemble et si et sont non corrélés, et ainsi que sont positives alors:
.
2)Application au filtre de Kalman-Bucy:
Pour cela on va supposer que tous nos vecteurs aléatoires sont des vecteurs gaussiens, que et sont indépendants de matrices de covariances et connues, et que est centré.
On pose .
Pour prédire à l'aide des premières observations on va poser et pour estimer par les premières observations on va poser .
On obtient par le théorème précédent une formule assez compliqué car il faut inverser une matrice de taile de plus en plus grande ce qui peut donc devenir très fastidieux.
Il est donc très utile de donner des formules de récurrence qui permette d'alléger les calculs des prédictions et des matrices d'erreurs.
On va noter par la suite et
On a
où et avec les conditions initiales
Et de la même manière on peut montrer que :
où
Preuve: Posons , par indépendance de on obtient (par indépendance de )
On a cela est évident par le fait que est indépendant de
Ainsi par le corollaire, on obtient que
Or
Ainsi
Ainsi montrer la première partie de la récurrence revient à montrer que
Or étant indépendant de , on a .
et le résultat final en découle par indépendance des 3 termes.
Ce qui permet de simplifier les calculs car les matrices à inverser sont de tailles constantes et qu'il suffit de connaitres les résultats à une étape précédente pour pouvoir calculer la suivante.
IV.Exhaustivité
Loi conditionnelle: Soit et deux variables aléatoires telles que admette une densité de probabilité .
On peut considérer la fonction
Où
Ceci nous permet de calculer des espérances conditionneles, ainsi
Application à la file d'attente: Soit où
Alors on a
Et
Ainsi
Définition: Une sous-tribu est dites exhaustive pour le modèle statistique si pour toute variable aléatoire réelle positive sur , il existe une version de l'espérance conditionnlle qui ne dépendent pas de .
Une statistique est dite exhaustive si l'est.
Proposition: Si est un estimateur sans biais de de carré intégrable et si est une statistique exhaustive alors l'estimateur est un estimateur sans biais de de risque quadratique plus faible que celui de de .
Définition: est une statistique complète si pour tout fonction telle que
Propriétés: Si est un estimateur sans biais de , de carré in tégrable et une statistique exhaustive et complète, l'estimateur est alors l'unique estimateur sans biais fonction de et sa variance est inférieur ou égal à la variance de et est même plus faible que celle de tout estimater sans biais.
Il est uniformément de variance minimum parmi les estimateurs sans biais.
Application Dans le cas de la file d'attente, est une statistique exhaustive et complète.
Donc est un estimateur UVMB indépendant de
Bibliographie
[R]: D.Revuz "Probabilités"
[BMP]: Baldi-Mazliak-Priouret "Martingales et chaînes de Markov"
[DCD]: Dacunha Castelle Duflo "Probabilités et statistiques 1"
[W]: Williams "Probability with Martingales"
[B]: Brémaud "Introducton aux probabilités"
[S]: Saporta "Probabilité-Analyse des données et statistiques"
[Sh]: Sheldon Ross
Publié par Tom_Pascal
le
ceci n'est qu'un extrait
Pour visualiser la totalité des cours vous devez vous inscrire / connecter (GRATUIT) Inscription Gratuitese connecter
Désolé, votre version d'Internet Explorer est plus que périmée ! Merci de le mettre à jour ou de télécharger Firefox ou Google Chrome pour utiliser le site. Votre ordinateur vous remerciera !
\\v(t)\end{pmatrix}=\begin{pmatrix}0&1\\-w^2&-\rho\end{pmatrix}\begin{pmatrix}x(t)\\v(t)\end{pmatrix})
) , et l'on ne dispose que de mesures discrètes portant sur la position du mobile:
, et l'on ne dispose que de mesures discrètes portant sur la position du mobile:
=GX(t)+W(t)) où
où  correpond au bruit perturbant l'appareil de mesure.
correpond au bruit perturbant l'appareil de mesure.
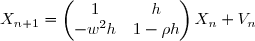
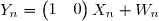
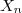 à partir des
à partir des  premières
observations, et l'autre d'estimer
premières
observations, et l'autre d'estimer 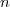 premières observations.
premières observations.
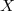 suit une loi
suit une loi ) ,
, 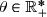 inconnue
inconnue
=P_{\theta}(X_1>t)) à partir de la connaissance du temps d'attente de
à partir de la connaissance du temps d'attente de 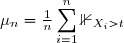 , cependant on va chercher un estimateur qui soit optimal en ce sens qu'il sera de variance inférieure.
, cependant on va chercher un estimateur qui soit optimal en ce sens qu'il sera de variance inférieure.
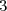 classes distinctes.
classes distinctes.
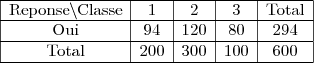 Soit
Soit 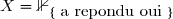 et
et 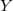 la classe de la personne.
la classe de la personne.
=P(X=1|Y=1)=0.47)
=\displaystyle\sum_{i=1}^3E(X|Y=i)\mathbb{1}_{Y=i}) .
.
_{i\in I}) et
et _{j\in J}) .
.
=\displaystyle\sum_{i\in I,j\in J}P(X=x_i|Y=y_j)x_i)
) un espace de probabilité.
un espace de probabilité.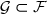 une sous tribu.
une sous tribu.
) , on appelle espérance conditionnelle de
, on appelle espérance conditionnelle de 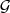 , la projection de
, la projection de ) et on la note
et on la note )
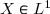 , alors il existe
, alors il existe <\infty) et
et 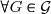
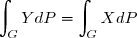 .
.
![Y=E[X|\cal G]](https://latex.ilemaths.net/latex-0.tex?Y=E[X|\cal G])
=E(X))
_{i\in {\mathbb{N}^*}}) est une partition de
est une partition de 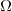 , avec
, avec 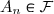 et
et 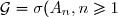) .Soit
.Soit =\displaystyle\sum_{i\in {\mathbb{N}}^*}E(X|A_i)\mathbb{1}_{A_i}) .
.
=\frac{E(X\mathbb{1}_{A_i})}{P(A_i)}) si
si \neq 0) et peut être choisi arbitrairement dans le cas contraire.
et peut être choisi arbitrairement dans le cas contraire.
_{i\in \lbrace 1,...,n\rbrace }) sont des va iid et
sont des va iid et 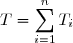 , on peut montrer que
, on peut montrer que ![E[T_1|T]=T/n](https://latex.ilemaths.net/latex-0.tex?E[T_1|T]=T/n) et
et ![E[T|T_1]=(n-1)E[T_1]+T_1](https://latex.ilemaths.net/latex-0.tex?E[T|T_1]=(n-1)E[T_1]+T_1) .
.
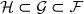 , alors
, alors =E(E(X|\cal G)|\cal H)) p.s.
p.s.
) martingale associée à
martingale associée à 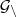 une filtration, alors à
une filtration, alors à 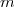 fixé,
fixé,
=X_m) .
.
) est constant.
est constant.
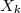 correspond a la proportion de boule blanche à la k-ème étape.
correspond a la proportion de boule blanche à la k-ème étape.
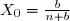 , on a
, on a ) qui est une martingale et
qui est une martingale et =E(X_0)=\frac{b}{n+b})
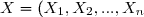^t) et
et 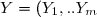^t) sont deux vecteurs aléatoires on définit
sont deux vecteurs aléatoires on définit =(E(X_1|Y),...,E(X_n|Y))^t) .
.
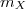 et
et 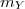 et de matrices de covariances
et de matrices de covariances 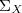 et
et 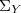 .
.
![\Sigma_{XY}=E[(X-m_X)(Y-m_Y)^t]](https://latex.ilemaths.net/latex-0.tex?\Sigma_{XY}=E[(X-m_X)(Y-m_Y)^t]) , et suppososns
, et suppososns =m_X+\S_{XY}\S_Y^{-1}(T-m_Y)) .
.
![\widetilde X=X-E[X|Y]](https://latex.ilemaths.net/latex-0.tex?\widetilde X=X-E[X|Y]) est
est  .
.
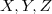 sont trois vecteurs gaussiens dans leur ensemble et si
sont trois vecteurs gaussiens dans leur ensemble et si 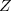 sont non corrélés, et
sont non corrélés, et 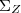 sont positives alors:
sont positives alors:
![E[X|Y,Z]=E[X|Y]+E[X|Z]-m_X](https://latex.ilemaths.net/latex-0.tex?E[X|Y,Z]=E[X|Y]+E[X|Z]-m_X) .
.
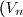_{n\in \mathbb{N}}) et
et 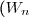_{n\in \mathbb{N}}) sont indépendants de matrices de covariances
sont indépendants de matrices de covariances 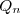 et
et 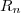 connues, et que
connues, et que 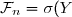) .
.
![{\widehat X}_n=E[X_n|{\cal F}_{n-1}]](https://latex.ilemaths.net/latex-0.tex?{\widehat X}_n=E[X_n|{\cal F}_{n-1}]) et pour estimer
et pour estimer ![{\widetilde X}_n=E[X_n|{\cal F}_n]](https://latex.ilemaths.net/latex-0.tex?{\widetilde X}_n=E[X_n|{\cal F}_n]) .
.
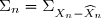 et
et 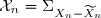
)
\Sigma_n(F-K_nG)^t+Q_{n+1}+K_nR_nK_n^t)
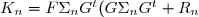^{-1}) et avec les conditions initiales
et avec les conditions initiales 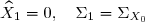
)
\Sigma_n)
^{-1})
![I_n=Y_n-E[Y_n|\mathcal{F}_n]=GX_n+W_n-E[GX_n+W_n|\mathcal{F}_n]](https://latex.ilemaths.net/latex-0.tex?I_n=Y_n-E[Y_n|\mathcal{F}_n]=GX_n+W_n-E[GX_n+W_n|\mathcal{F}_n]) , par indépendance de
, par indépendance de 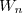 on obtient
on obtient +W_n)
![\Sigma_{I_n}=E[I_nI_n^t]=GS_nG^t+R_n](https://latex.ilemaths.net/latex-0.tex?\Sigma_{I_n}=E[I_nI_n^t]=GS_nG^t+R_n) (par indépendance de
(par indépendance de 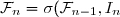) cela est évident par le fait que
cela est évident par le fait que 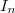 est indépendant de
est indépendant de 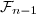
![{\widehat X}_{n+1}=E[X_{n+1}|\mathcal{F}_n]=E[X_{n+1}|\mathcal{F}_n]+E[X_{n+1}|I_n]=F{\widehat X}_n+FE[X_n|I_n]](https://latex.ilemaths.net/latex-0.tex?{\widehat X}_{n+1}=E[X_{n+1}|\mathcal{F}_n]=E[X_{n+1}|\mathcal{F}_n]+E[X_{n+1}|I_n]=F{\widehat X}_n+FE[X_n|I_n]) Or
Or ![FE[X_n|I_n]=\Sigma_{X_nI_n}S_{I_n}^{-1}I_n](https://latex.ilemaths.net/latex-0.tex?FE[X_n|I_n]=\Sigma_{X_nI_n}S_{I_n}^{-1}I_n)
^{-1}(Y_n-G{\widehat X}_n))
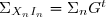
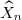 étant indépendant de
étant indépendant de 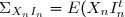=E((X_n-{\widehat X}_n)I_n^t)=\Sigma_nG^t) .
.
)=F(X_n-{\widehat X}_n)+V_n-K_n(GX_n+W_n-G{\widehat X}_n)=(F-K_nG)(X_n-{\widehat X}_n)+V_n-K_nW_n) et le résultat final en découle par indépendance des 3 termes.
et le résultat final en découle par indépendance des 3 termes.
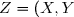) admette une densité de probabilité
admette une densité de probabilité }(x,y)) .
.
}(x,y) = \left\lbrace \begin{array}{ll} \frac{f_{(X,Y)}(x,y)}{f_Y(y)} & \qquad \mathrm{si}\quad f_Y(y)>0 \\ 0 & \qquad \mathrm{sinon} \\ \end{array} \right.)
=\int_{\mathbb{R}}f_{(X,Y)}(x,y)dx)
![E[g(X)|Y]=\int_{\mathbb{R}}g(x)f_{(X|Y)}(x,Y)dx](https://latex.ilemaths.net/latex-0.tex?E[g(X)|Y]=\int_{\mathbb{R}}g(x)f_{(X|Y)}(x,Y)dx)
![T_{\theta}=E_{\theta}[\mu_n|S_n]P_{\theta}(X_1>t|S_n)](https://latex.ilemaths.net/latex-0.tex?T_{\theta}=E_{\theta}[\mu_n|S_n]P_{\theta}(X_1>t|S_n)) où
où 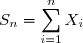
}(x,y)=\theta^n e^{-\theta y}\frac{(y-x)^{n-2}}{(n-2)!}\mathbb{1}_{0\le x\le y})
=\theta^ne^{-\theta y}\frac{(-y)^{n-1}}{(n-1)!}\mathbb{1}_{y\ge 0})
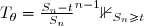
) si pour toute variable aléatoire réelle positive
si pour toute variable aléatoire réelle positive 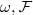 , il existe une version de l'espérance conditionnlle
, il existe une version de l'espérance conditionnlle ![E_{\theta}[X|\cal G]](https://latex.ilemaths.net/latex-0.tex?E_{\theta}[X|\cal G]) qui ne dépendent pas de
qui ne dépendent pas de 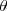 .
.
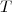 est dite exhaustive si
est dite exhaustive si ) l'est.
l'est.
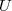 est un estimateur sans biais de
est un estimateur sans biais de ) de carré intégrable et si
de carré intégrable et si ![V=E[U|T]](https://latex.ilemaths.net/latex-0.tex?V=E[U|T]) est un estimateur sans biais de
est un estimateur sans biais de ![E_{\theta}[(V-h(\theta))^2]\le E_{\theta}[(U-h(\theta))^2]](https://latex.ilemaths.net/latex-0.tex?E_{\theta}[(V-h(\theta))^2]\le E_{\theta}[(U-h(\theta))^2])
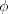 fonction telle que
fonction telle que \in L^1)
P_{\theta}=0\;p.s\quad\forall \theta \Rightarrow \phi=0\;P.p.s)
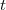 une statistique exhaustive et complète, l'estimateur
une statistique exhaustive et complète, l'estimateur ![E[U|T]](https://latex.ilemaths.net/latex-0.tex?E[U|T]) est alors l'unique estimateur sans biais fonction de
est alors l'unique estimateur sans biais fonction de 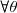 inférieur ou égal à la variance de
inférieur ou égal à la variance de 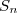 est une statistique exhaustive et complète.
est une statistique exhaustive et complète.
![E_{\theta}[\mu_n|T]](https://latex.ilemaths.net/latex-0.tex?E_{\theta}[\mu_n|T]) est un estimateur UVMB indépendant de
est un estimateur UVMB indépendant de parmi les fonctions
et en particulier
.
 Forum enseignement
Forum enseignement